In our recent webinar on course parsing standardized content for artificial intelligence, we received a number of questions on how to approach content utilization with emerging tech. We’ll take some time to answer those questions and point you in the right direction.
Imagine your eLearning courses as a vast and valuable library of books. Each book has different and useful information, but they’re uncatalogued and jumbled in boxes and piles. You’ve been told you can use this knowledge to build new and exciting things, but without a proper system in place, you can’t find the specific information you need inside them. This is what many have encountered when exploring new learning technologies to repurpose and revitalize standardized training content. This problem has only become more prominent with the rise of AI.
Tools and Technologies on the Horizon
So what are the tools and technologies out there promising a new way to interact and use your valuable training content?
Through our own conversations and with reports coming out from the Learning Guild on Workplace Learning Technologies Adoption and Fosway on Fosway AI Market Assessment for Learning Systems, we’ve seen a growing number of people trying to build things like:
- AI-Powered Chatbots and Tutors: Instead of a generic chatbot, companies are building AI assistants trained on their existing course material to provide real-time, conversational support to learners. These tools can offer instant feedback, answer questions and provide guided tutorials. Fosway’s research on AI features shows that while AI-driven assistants acting as a study buddy or tutor are still in the early stages of adoption, they are on vendor roadmaps for future development.
- Advanced Search and Content Discovery: The “search” button in a traditional learning management system (LMS) often only looks at a course title or basic tags. The next generation of search allows a learner or administrator to find information within a course or a full catalog, surfacing relevant videos, quizzes or slides. This requires a complete, searchable index of the content, which is a key goal for platforms looking to use tools like Elasticsearch or Apache SOLR to enhance search functionality. This is a major area of vendor focus as reported by Fosway and Learning Guild, as companies are building “intelligent search with answers provided via NLP/chatbot functionality.”
- Automated Skill Tagging: Beyond intelligent search, another crucial development highlighted by these reports is the “automated tagging of content with skills.” This involves leveraging AI and machine learning to automatically assign relevant skills and competencies to learning materials. This allows organizations to utilize or create a more robust and dynamic skills taxonomy, making it far easier for learners to find the precise resources they need to develop specific capabilities. This automated tagging not only improves discoverability but also lays the groundwork for more personalized learning paths and adaptive recommendations.
- Personalization and Analytics: Speaking of personalized learning, the holy grail of learning is a truly personalized experience. New tools are being developed that can analyze content and then use that data to create “personalized learning paths” for each student. Learning Guild reports this is a top motivation for technology adoption, with 45% of L&D professionals prioritizing it. Fosway’s research confirms this is a major focus for vendors, as they are building “AI-powered adaptive engines” to continuously personalize the learner experience and provide “smart AI-driven personalized recommendations of content and people”.
- Generative AI for Content and Assessments: Generative AI is not just about creating brand-new content from a blank slate. Learning Guild data from a recent survey confirms, generative AI for content development is an emerging tool in the learning ecosystem, with a 52.8% adoption rate. Fosway confirms vendors are actively developing features to automatically create assessments, quizzes and even entire courses based on existing content, making it easier to rapidly populate a learning system. This also includes “AI-enabled translation of courses and resources,” a feature nearly at mainstream adoption.
The Unsorted Shelves
While these tools have a lot of promise to make things more efficient and improve learner outcomes, the value lies inside your content. These all are trying to build toward having a strong link between the tool, learner and what’s inside a course, but the organization of data inside of your learning materials can be a roadblock. Plus, if you start building toward any of these solutions without thinking through this key first step, in this case how to fully access training course text and data, you aren’t setting yourself up for success in the long run.
Where we see the biggest lift with customers trying to extract information from inside a course is with standardized training courses. Each eLearning standard, like SCORM or xAPI, is implemented differently across various authoring tools. While the standards provide the “MUSTs” and “SHOULDs”/”SHALLs” for content to work with a learning system, they often lack the explicit rules that would make it easy to extract text or data from inside it. The result is a messy assortment of folders, inconsistent file structures and disparate code—all of which a human can laboriously interpret but a machine struggles to comprehend.
For example, a course from one authoring tool might organize its content by slides, while a course from another might break it down by topics or a single data object. This inconsistency means a generic, one-size-fits-all approach to utilizing your training is like trying to find a book on “carbon emissions” when you don’t know if the book is filed by the author’s name, the subject or the color of the cover.
This challenge has existed for years, long before AI became a major business focus. It’s a key reason why many AI models struggle to effectively use learning content today and why emerging learning tech has missed its full potential in content utilization.
Our Universal Catalog
This is where our team comes in. At Rustici Software, we’ve been working with these standards for more than 20 years, so we understand the complexities of each unique organizational system.
Rustici Generator is your professional librarian. It can go through your entire collection—regardless of the authoring tool or standard—and create a universal, searchable catalog. The process Generator uses is called “course parsing,” and it’s a systematic way of extracting data from something like a SCORM or cmi5 package. Course parsing allows you to pull out all the content and data from your courses, like course text, questions, embedded media and other metadata that all live inside your course package hidden away. Generator doesn’t create new content; it’s the essential foundation that allows you to take that parsed out text and metadata to then leverage the content on another level. With this raw text, resources and metadata at your fingertips, you can use it to improve on existing functionality or build towards new ways to interact or search through your courses.
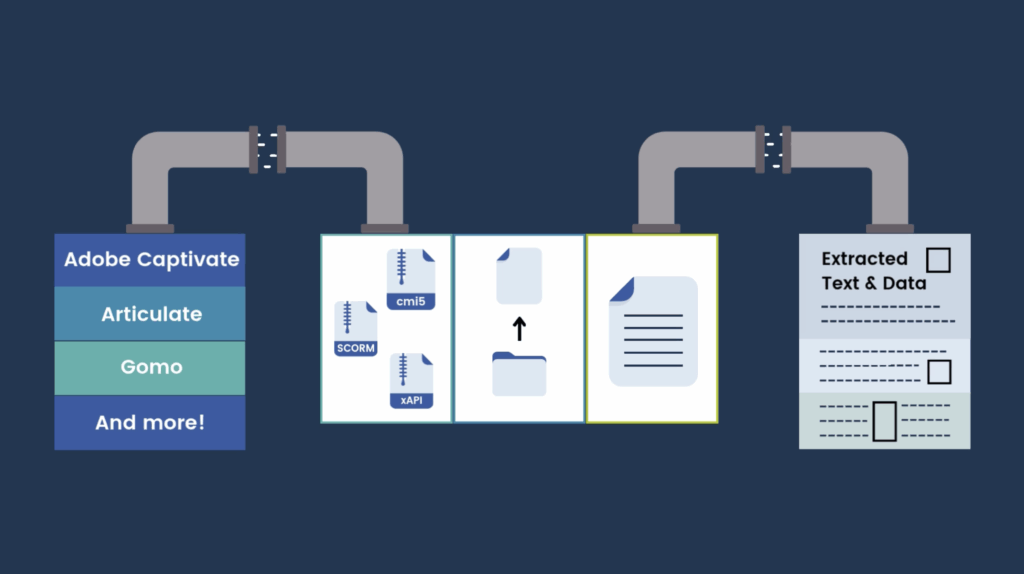
For example, let’s look at the impact this has on Advanced Search in an LMS. Without a proper course parsing tool extracting text and data from your course, your search function is limited. You only have access to surface-level metadata like titles, keywords or descriptions, if they are even filled out correctly. You might be looking for information about “Dewey Decimal System,” but your LMS can only find courses with that exact phrase in the title. You quickly find yourself manually sifting through courses to only find that the course title was misspelled or the title is misleading to what you’re looking for inside the content.
When you fuel your search engine with the course parsing data that Generator provides, it’s like having a catalog that has the precise location of every single piece of information. Now, when a learner searches for “Dewey Decimal System,” the search engine can surface not just the courses with the right title, but also the exact slide, video or document that contains the relevant or similar information. This is how you go from a basic, frustrating search to a smart, powerful one.
What’s Next?
Once you have the library of data inside your courses clearly understood, the possibilities for using your content are limitless. You can use a library of training to build a wide range of applications that will improve any learning ecosystem.
The first step is to ask your teams and vendors: “How is data collected from inside your content that fuels the application’s tools?”
Once you have a course parsing solution that finds and organizes all the data inside your course, you will have all the knowledge you need to build the future of eLearning.
If you are interested in learning more about how we’re approaching content data extraction, you can reach out to our team to learn more about Rustici Generator. You can also check out our quick demo on the tool or watch our recent webinar on content data extraction.


