How does it work?
Traditionally, knowing what is inside your content in your library involves scanning through courses, watching from beginning to end or trying to get a hold of the creator, which is a time-consuming chore. Rustici Generator can help by using content parsing! Content parsing works by extracting course text, media files, PDFs, interactions and more from the content and serves it up as a JSON file. With that file in hand, you can pull that into your LMS via API to enhance any tool that aims to repurpose, find or make training interactive.
All course content is different. This is not just between SCORM, cmi5 and other standards, but content also differs significantly between authoring tools. There are no rules in place for where course content has to be located within a SCORM file, so each authoring tool can vary in its approach. That’s why it is so important to not take a one-size-fits-all approach to parsing text and assets from your content. Rustici Generator has individual parsers per authoring tool that intimately know how authoring tools structure their course files to find everything in your training. Now, instead of manually scraping through a course to find where compliance code “A” is found, you can pull the extracted text into your search tools, chatbots etc, to know exactly where and on which slide it can be found.
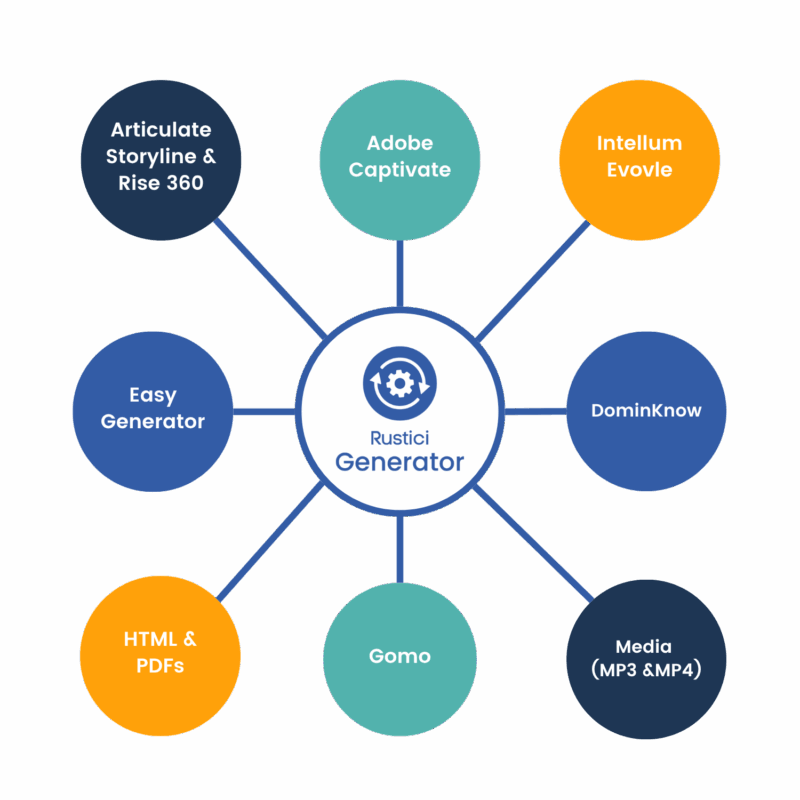
What content can be parsed?
These are the current formats that are supported by Rustici Generator, but if you have another that you want to see on this list make sure to reach out to our team!
Supported file types
- MP4
- MP3
- Web pages
- Raw text
Supported eLearning content packages
- Text, PDF, MP3/4 and Interaction extraction
- Articulate Storyline
- Articulate Rise 360
- Adobe Captivate
- Intellum Evolve
- Gomo (PDF & Interactions only)
- Text extraction only
Have questions about our content parsing tools?
Reach out to our team to ask us anything!